

Introduction
Data literacy is the combination of a few unique skill sets: statistical literacy, information literacy, and technical proficiency. It also involves being able to visualize, critically evaluate, determine the accuracy and reliability of, and understand data sets. There are many reasons why it is important to be data literate, especially in recent years with the advent of the internet and social media. Data literacy is also crucial to many different industries and research areas. It is important to interpret the data that you are collecting to make sure that the results are accurate and to be able to understand that data so that you can create useful visualizations for others.
There are a variety of concepts to keep in mind when critically evaluating data. For example, you need to consider the methods that were used to collect the data and whether those methods are ethical. Furthermore, when evaluating how the data is presented, you need to consider whether that representation or visualization is the most accurate way to portray the data. Another particular topic of concern is bias. There are different points at which biases can be introduced, such as when data is collected, when it is analyzed, and when it is shared with the public. Also, if you are critically evaluating your own data, it is important to check that there are no biases within your own work. In this post we will be discussing the critical evaluation of data through the lens of data collection, data presentation and visualization, and data ethics.
Data Collection
In the context of data collection, several different collection methods can be used for research. Some of these methodologies, such as focus groups, surveys, and participant interviews, are familiar to the public at large. However, there are other specific data collection processes that many people outside of certain academic disciplines may not be aware of, such as web scraping/text mining, phlebotomy procedures for blood tests, observational behavior recording for time series data, and many more.
Consequently, not only is recording the data itself of importance for experimental duplication purposes, but it can also be important for interdisciplinary work. Some fields of research may have different research data collection methods that researchers in other fields may not be aware of, even across seemingly similar disciplines. For example, accounting and finance may seem similar but can have drastically different ways of interpreting monetary data. The way accountants and financial analysts calculate when a company is at a net zero (i.e., a break-even) between revenues and costs is different. Even within the same field of research, transparency with how data is collected is important for peer review – whether it be for ethics accountability or determining methodological flaws within research. An incomplete set of data can make it difficult or impossible to know whether or not the data was collected in a way to prevent bias, and further make it impossible to know if the data is accurate and/or precise.
Failing to document data and data collection methods can also create problems reproducing or using the data for further research, particularly if things such as question types, experiment conditions, and units of measure are not properly documented. For example, while the hypothetical idea of cold fusion (nuclear fusion performed at room temperature) would be a low-cost energy solution, the experimental methods and data were not recorded. As a result, the concept of cold fusion is now widely looked at with skepticism because none of the data was recorded! A less extreme case where incomplete data may cause research problems is that the way that a survey is constructed can bias responses. Therefore, documenting how a survey was written can be helpful in evaluating why a research study came to a specific conclusion, as well as testing whether or not changing questions or even question order would change results.
Furthermore, data cleaning – which is the process in which things such as incorrectly formatted data, corrupted data, etc are reformatted or fixed so that it can be used in analysis – can also contribute to statistical bias(es) via things such as eliminating outliers, accidentally losing a variable, how you decide to categorize your data, and more. Therefore, documenting how you clean your data is also a critical component of research – explaining what outliers you decided to keep or remove and why can help you and other researchers down the road. It is also important to consider the order questions are asked in and the way questions are worded when conducting surveys. While it might seem counterintuitive at first, the way that questions are ordered and worded can impact the percentages of people that respond in a certain way, whether or not potential participants qualify for research projects, and even the numeric values of the data itself.
Data Presentation and Visualization
Most have probably heard the phrase “label your axes” at some point, even before college. It is often mentioned in K-12 education, with the pretense being that someone will not know what your graph(s) are depicting without them. While this is indeed correct, labeled axes constitute only one of many different components of data presentation and visualization.
Figure 1: Axes that are labeled!
A good place to start on the types of ways that data visualizations can be best implemented would be The Data Visualisation Catalogue. While the site was originally established with graphic designers in mind, Severino Ribeccca himself stated “I felt it would also be beneficial to…anyone in a field that requires the use of data visualisation.”(Ribecca n.d.) As such, almost anyone who uses data typically has to consider how to visually communicate data in a way to an outside audience, or even the general public outside of the realm of academia. A nifty feature of The Data Visualisation Catalogue is that there is a way to filter recommended data visualization types by what concept you are trying to demonstrate.
One consideration when looking at a data visualization is whether the data is represented in a way that is appropriate for that specific data type. While it might not seem like the data presentation would differ between data types, certain visualizations will serve to more accurately and sufficiently depict different types of data. For instance, data related to time and Geographic Information Systems mapping produce distinct data types. While they can be combined and represented in the same graphic (i.e., how has the land of a certain area changed over time?), they both have their own distinct issues to consider to make sure that you are not creating misleading graphics. Namely, one cannot make a map with time data alone, and a map would be hard to make with a line graph that is meant to show trends in time.
Furthermore, the scales and units that are utilized in a data representation are also important considerations! Using our previous example, we can note that the visual scales of a map are different from the visual scales of time series data. For instance, you can get drastically different data visualizations if you transform data from a linear scale to a logarithmic scale (i.e., a scale that plots data based on what exponent would be needed to get your number back). This can be useful for situations where the data you are working with is so large that it is hard to see everything in an efficient way. For example, a logarithmic scale of time where millions of years are condensed into smaller numbers that are easier to conceptualize leads to graphs where you can see things like different geographical eras.
On a more human scale, while logarithmic data could be used to misrepresent data, a far more common tactic for misrepresenting data involves a truncated or broken axis on a graph (Figures 2a and 2b); a truncated graph deliberately not starting at zero on the y-axis, and a broken axis subtly skipping a large amount of units. This is a common tactic that is present in some graphics that news outlets might use, whether it is intentional or not. Some other characteristics of misrepresented data might be plotting two graphs that are not on the same scale or zooming your scale in to make a trend look far larger than it truly is.
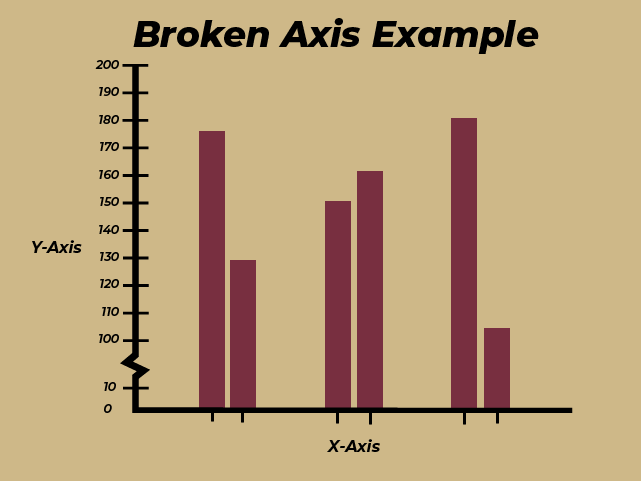
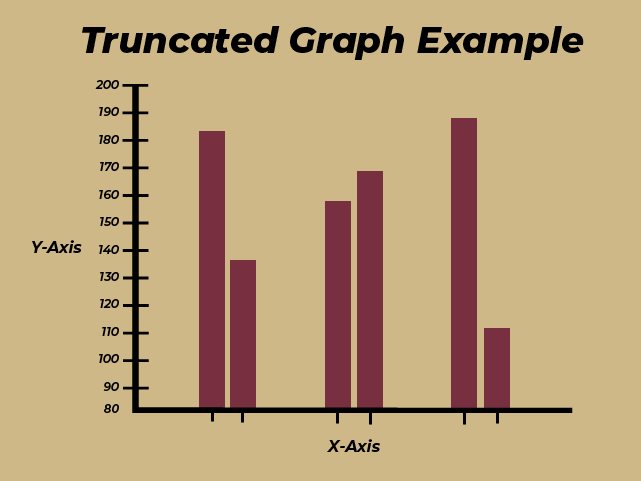
Figures 2a and 2b: Graphical Examples of a graph with a broken axis and a graph with a truncated axis, respectively
While there are many examples of distinctly misleading graphs, there are also many graphs that accurately portray the data, but use an incompatible or inaccessible color palette. Related to this, many color palettes used in data visualizations can be inaccessible to those with vision impairments such as green-red and blue-yellow color blindness. Utilizing distinct color-blind friendly palettes can help to make visualizations more accessible. Furthermore, using alt-text descriptions of what the graph is showing enhance the ability of screen readers and other tools utilized by those with low-vision and blindness to interpret the visualization. Thus, being hard to see or just looking aesthetically displeasing does not make a graph misleading, and is an important distinction to make (although the two are not mutually exclusive!)
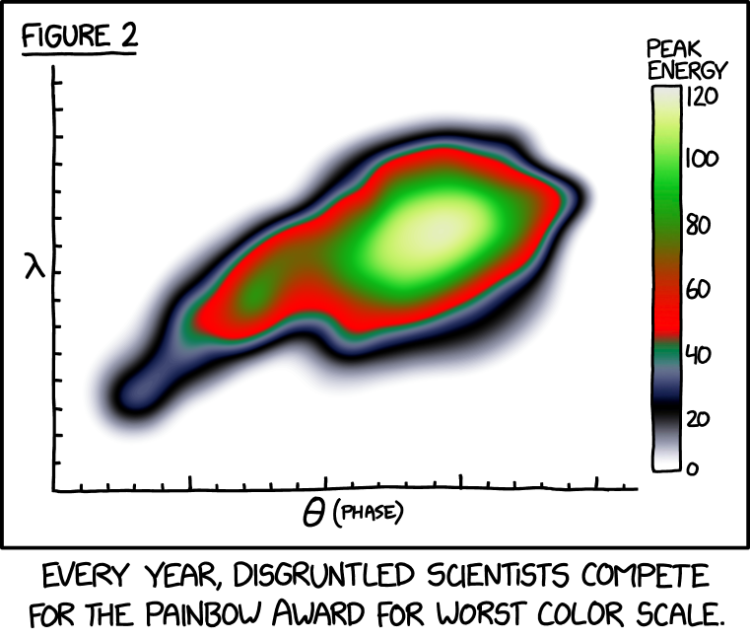
Figure 3: A “Painbow” Graph
Data ethics
When examining a dataset, it is also important to consider whether there are any biases present that may affect interpretation of the data. Two common categories of biases are cognitive biases and statistical/algorithmic biases. Cognitive biases involve individuals interpreting the results of a study to best fit a specific narrative. This may involve a data producer deleting data that does not fit the conclusion that they are trying to prove. At the same time, a data producer may also add data that is not accurate in an attempt to strengthen their claims. Furthermore, studies may be designed to collect data that only represents a small subset of a population, while claiming to be representative of the entire population.
Similar to cognitive biases, statistical/algorithmic biases describe the concept of bias as your sample poorly describing your population. In that context, it is significantly mitigated (if not outright eliminated) if your data collection methods are not generally or statistically biased. This is particularly noticeable when examining artificial intelligence (AI) algorithms. These algorithms are often trained with unequal datasets, which then leads to skewed results when performing data analysis with said algorithms. Therefore, when examining data that is outputted by an algorithm, one should consider whether the algorithm has been trained with accurate and equal data sets. An industry where statistical and algorithmic biases are extremely important to consider is the healthcare industry. For example, many hospitals use artificial intelligence to sort through patient data, which helps doctors determine who needs immediate emergency attention. While there are many benefits to such algorithms, there have been issues in the past because of them. In certain instances, if a patient has pre-existing medical conditions that affect their health, the algorithm will not be able to take that into account. In addition, many algorithms that are commonly used in healthcare systems are racially and gender biased. As mentioned in “Algorithmic Bias in Health Care Exacerbates Social Inequities — How to Prevent It” written by Katherine Igoe, “algorithms in health care technology don’t simply reflect back social inequities but may ultimately exacerbate them.” Igoe also mentions that certain prediction algorithms used for detecting heart diseases in the medical industry were biased in their design. For example, the “Framingham Heart Study cardiovascular risk score” worked very well for caucasion patients, but not for African American patients. This is due to the fact that around 80% of the collected data used for this algorithm was from caucasian patients. Utilizing such an unequal dataset to train the algorithm can lead to unequal care and treatment in medical practices (Igoe). This example is just one of the many examples of bias due to algorithm design.
Companies such as Amazon have also faced huge problems relating to algorithm bias. A few years ago, Amazon tried to utilize an algorithm that used artificial intelligence to hire new employees. However, it turned out that this algorithm was biased against women. This is because the algorithm was trained on resumes that were submitted during a time period where the number of male applicants was significantly higher than the number of female applicants. This ultimately caused the algorithm to be trained to favor men over women.
Conclusion
Critical evaluation of data is an extremely important skill set for any student or professional to have. Knowing the importance of checking the reliability, accuracy, and the bias in any data set is necessary when reading or working with data. Some questions to keep in mind are: is the collection method clear and documented? Is the data visualization appropriate for the dataset and for what the author is trying to represent? Is the data biased in the collection or visualization stages? It is important to evaluate data to ensure that we are using quality and accurate data to make sound decisions and conclusions.
Works Cited
- Aldridge, Christine. 2019. “Accounting Vs. Financial Break Even Point.” ..Com. The Houston Chronicle. January 11, 2019. https://smallbusiness.chron.com/accounting-vs-financial-break-even-point-31235.html.
- Alessandro, Brian d’, Cathy O’Neil, and Tom LaGatta. “Conscientious Classification: A Data Scientist’s Guide to Discrimination-Aware Classification.” ..Org. Cornell University ArXiv, July 21, 2019. https://arxiv.org/abs/1907.09013.
- Barocas, Solon, and Elizabeth Bradley. “Big Data, Data Science, and Civil Rights.” ..Net. Research Gate, 2017. https://www.researchgate.net/publication/317558092_Big_Data_Data_Science_and_Civil_Rights.
- Codecademy Team. “Bias in Data Analysis.” ..Com. Codecamedy. Accessed November 29, 2022. https://www.codecademy.com/article/bias-in-data-analysis.
- Colour Blind Awareness. 2022. “Types of Colour Blindness.” ..Org. Colour Blind Awareness. 2022. https://www.colourblindawareness.org/colour-blindness/types-of-colour-blindness/.
- Edwards, Brent D. 2019. “Edwards, D. Brent. “Best Practices from Best Methods? Big Data and the Limitations of Impact Evaluation in the Global Governance of Education.” Edwards, D. Brent. “Best Practices from Best Methods? Big Data and the Limitations of Impact Evaluation in the Global Governance of Education. 39: 69–85. https://doi.org/10.1108/S1479-367920190000038005.
- Fatima, Nausheen. 2021. “Data Visualization Examples: Good, Bad and Misleading.” ..Com. Syntax Technologies. December 17, 2021. https://www.syntaxtechs.com/blog/data-visualization-examples.
- Fluffware. n.d. Always Label Your Axes. Comic. 500×475 pixels. Accessed November 22, 2022. https://flowingdata.com/2012/06/07/always-label-your-axes/.
- Gilet, Candace. n.d. “Cold Fusion: A Case Study in Scientific Behavior.” ..Edu. University of California – Berkeley : Understanding Science. Accessed December 1, 2022. https://undsci.berkeley.edu/cold-fusion-a-case-study-for-scientific-behavior/.
- Goedhart, Joachim. 2019. “Data Visualization with Flying Colors.” ..Com. The Node. August 29, 2019. https://thenode.biologists.com/data-visualization-with-flying-colors/research/.
- Gott, J. Richard, and Mario Juric. 2006. “Logarithmic Maps of the Universe.” ..Edu. Princeton.Edu. 2006. https://www.astro.princeton.edu/universe/.
- Hoffman, Nicholas von, Irving Louis Horowitz, and Lee Rainwater. “Sociological Snoopers and Journalistic Moralizers: An Exchange.” Trans-Action (Philadelphia) 7, no. 7 (1970): 4–. https://link.springer.com/content/pdf/10.1007/BF02804293.pdf
- Igoe, Katherine. “Algorithmic Bias in Health Care Exacerbates Social Inequities — How to Prevent It.” ..Edu. Harvard School of Public Health, March 12, 2021. https://www.hsph.harvard.edu/ecpe/how-to-prevent-algorithmic-bias-in-health-care/.
- Lavalle, Ana, Alejandro Mate, and Juan Trujillo. “An Approach to Automatically Detect and Visualize Bias in Data Analytics.” CEUR, Proceedings of the 22nd International Workshop on Design, Optimization, Languages and Analytical Processing of Big Data co-located with EDBT/ICDT 2020 Joint Conference (EDBT/ICDT 2020), 2572 (March 30, 2020). https://rua.ua.es/dspace/bitstream/10045/104029/1/2020_Lavalle_etal_DOLAP.pdf.
- Lerouge, Frederik. 2015. Geologic Time Scale. Digital Media. 423 × 599 pixels. https://commons.wikimedia.org/wiki/Category:Geologic_time_scale#/media/File:Geologic_Time_Scale.png.
- Loo, Mark van der, and Edwin de Jonge. Statistical Data Cleaning with Applications in R. Hoboken, NJ: John Wiley & Sons, Inc., 2018.
- Mark, Melvin, Kristen Eysell, and Bernadette Campbell. “The Ethics of Data Collection and Analysis.” New Directions for Evaluation, 1999 1999, no. 82 (November 5, 2004): 47–56. https://doi.org/10.1002/ev.1136.
- Mitchell, Cory. 2022. “Break-Even Point: Definition, Examples, and How to Calculate.” ..Com. Investopedia. March 2, 2022. https://www.investopedia.com/terms/b/breakevenpoint.asp.
- Munroe, Randall. n.d. Painbow Award. Digital Media. 761×648 pixels. Accessed November 22, 2022. https://xkcd.com/2537/.
- Munzert, Simon. Automated Data Collection with R : a Practical Guide to Web Scraping and Text Mining. Chichester, West Sussex, United Kingdom ;: Wiley, 2014. https://fsu-flvc.primo.exlibrisgroup.com/permalink/01FALSC_FSU/p5gnan/alma990358902540306576
- National Geographic. n.d. “GIS (Geographic Information System).” ..Org. GIS (Geographic Information System). Accessed November 22, 2022. https://education.nationalgeographic.org/resource/geographic-information-system-gis.
- Oldendick, Robert W. 2008. “Question Order Effects.” In Encyclopedia of Survey Research Methods, edited by Paul J. Lavrakas, 664–65. Thousand Oaks, CA: Sage Publications, Inc. https://dx.doi.org/10.4135/9781412963947.n428.
- O’Neil, Cathy. “Amazon’s Gender-Biased Algorithm Is Not Alone.” ..Com. Bloomberg, October 16, 2018. https://www.bloomberg.com/opinion/articles/2018-10-16/amazon-s-gender-biased-algorithm-is-not-alone?leadSource=uverify%20wall.
- Paradise, Elise, Bridget O’Brien, Laura Nimmon, Glen Bandiera, and Maria Athina (Tina) Martimianakis. 2016. “Design: Selection of Data Collection Methods.” Journal of Graduate Medical Education 8 (2): 263–64. https://doi.org/10.4300/JGME-D-16-00098.1.
- Pennsylvania State University. n.d. “4.3 – Statistical Biases.” ..Edu. STAT 509 Design and Analysis of Clinical Trials. Accessed November 17, 2022. https://online.stat.psu.edu/stat509/lesson/4/4.3.
- Pew Research Center. n.d. “Writing Survey Questions.” ..Org. Https://Www.Pewresearch.Org. Accessed December 6, 2022. https://www.pewresearch.org/our-methods/u-s-surveys/writing-survey-questions/.
- Pierce, Christian. n.d. “Data Collection Methods.” ..Edu. Https://People.Uwec.Edu/Piercech/. Accessed November 15, 2022. https://people.uwec.edu/piercech/researchmethods/data%20collection%20methods/data%20collection%20methods.htm.
- Pratt, Wanda. n.d. “Observational Field Research.” ..Edu. University of Washington. Accessed November 17, 2022. https://faculty.washington.edu/wpratt/MEBI598/Methods/Collecting%20Data%20Through%20Observation.htm.
- The Qualitative Data Repository, and Syracuse University. n.d. “Principles of Documenting Data.” ..Org. https://Managing-Qualitative-Data.Org/. Accessed November 17, 2022. https://managing-qualitative-data.org/modules/2/a/.
- Ribecca, Severino. n.d. “About the Data Visualisation Catalogue.” ..Com. The Data Visualisation Catalogue. Accessed November 22, 2022. https://datavizcatalogue.com/about.html.
- Ribecca, Severino. n.d. “What Do You Want to Show?” ..Com. The Data Visualisation Catalogue. Accessed November 22, 2022. https://datavizcatalogue.com/search.html.
- Ribecca, Severino n.d. “Data Viz Catalogue.” ..Com. The Data Visualisation Catalogue. Accessed April 14, 2022. https://datavizcatalogue.com/.
- Routledge, R.. “law of large numbers.” Encyclopedia Britannica, n.d. https://www.britannica.com/science/law-of-large-numbers.
- Shin, Terence. “Real-Life Examples of Discriminating Artificial Intelligence.” ..Com. Medium, October 4, 2020. https://towardsdatascience.com/real-life-examples-of-discriminating-artificial-intelligence-cae395a90070.
- Shin, Terence. 2022. “What Is Statistical Bias and Why Is It so Important in Data Science?” ..Com. Towards Data Science. February 18, 2022. https://towardsdatascience.com/what-is-statistical-bias-and-why-is-it-so-important-in-data-science-80e02bf7a88d.
- Silva, Selena, and Martin Kenney. “How Computing Platforms and Algorithms Can Potentially Either Reinforce or Identify and Address Ethnic Biases.” ..Org. ACM Digital Library, October 24, 2019. https://dl.acm.org/doi/fullHtml/10.1145/3318157.
- Springer. n.d. “Data Fabrication / Data Falsification.” ..Com. Springer.Com. Accessed November 29, 2022. https://www.springer.com/gp/authors-editors/editors/data-fabrication-data-falsification/4170.
- Tableau, “5 Tips on Designing Colorblind-Friendly Visualizations.” n.d. ..Com. Accessed November 22, 2022. https://www.tableau.com/blog/examining-data-viz-rules-dont-use-red-green-together.
- Tableau. n.d. “Guide To Data Cleaning: Definition, Benefits, Components, And How To Clean Your Data.” ..Com. Tableau.Com. Accessed November 22, 2022. https://www.tableau.com/learn/articles/what-is-data-cleaning.
- Tucker, Trent. 2018. Cases and Tools in Biotechnology Management. How Graph Misrepresents Data 9. https://ecampusontario.pressbooks.pub/bio16610w18/chapter/how-graph-misrepresents-data/.
- University of Ottawa. “Introduction to Finding Data and Statistics.” ..Com. uOttawa. Accessed November 29, 2022. https://uottawa.libguides.com/intro-datastats-eng/cite.
- U.S. Department of Health & Human Services. n.d. “Responsible Conduct in Data Management.” ..Gov. Responsible Conduct in Data Management. Accessed November 15, 2022. https://ori.hhs.gov/education/products/n_illinois_u/datamanagement/dctopic.html.
- Villar, Ana. “Response Bias.” In Encyclopedia of Survey Research Methods, edited by Lavrakas, Paul J., 752-53. Thousand Oaks, CA: Sage Publications, Inc., 2008. https://dx.doi.org/10.4135/9781412963947.n486.
- World Health Organization. 2010. WHO guidelines on Drawing Blood: Best Practices In. World Health Organization. https://www.euro.who.int/__data/assets/pdf_file/0005/268790/WHO-guidelines-on-drawing-blood-best-practices-in-phlebotomy-Eng.pdf.
- Zewe, Asam. 2022. “Making Data Visualization More Accessible for Blind and Low-Vision Individuals.” ..Edu. MIT News. June 2, 2022. https://news.mit.edu/2022/data-visualization-accessible-blind-0602.
{kind=link}
This blog post was written by William-Elijah Clark (Senior STEM Data Fellow) and Reagan Bourne (STEM Data Fellow) from FSU Libraries.